Serving Multiple HTML Clients from a Prolog Application
Péter Szeredi, Katalin Molnár, and Rob Scott(*)
IQSOFT Intelligent Software Ltd.
H-1142 Teleki Blanka u. 15-17
Budapest, Hungary
E-mail: {szeredi,molnark,scott}@iqsoft.hu
Péter Szeredi, Katalin Molnár, and Rob Scott(*)
IQSOFT Intelligent Software Ltd.
H-1142 Teleki Blanka u. 15-17
Budapest, Hungary
E-mail: {szeredi,molnark,scott}@iqsoft.hu
Abstract:
We briefly present the expert system and describe the experiences of its transformation to the HTML-based user interface. We then focus on the issue of designing a single Prolog server capable of serving multiple client requests.
We present a solution based on an or-parallel Prolog system, Aurora. This approach allows the server to perform independent Prolog searches for each client, controlled interactively by the remote user.
Keywords: Expert systems, HTML, Client-server architectures, Prolog, Parallelism
Our efforts are an example of a general trend in the AI community, to use the extended visibility that WWW provides to make applications available through the Internet. In order to interact with end-users through the WWW, such applications normally rely on socket-based inter-process communication features. Most commercial Prolog systems (ALS, Quintus, SICStus, etc.) already have such features implemented. Tools have also been developed for helping the communication with the end-user, such as the CGI handler interface of [5] and the support functions of html.pl [4] for generating HTML documents from Prolog.
One of the major issues that, we believe, have not been addressed so far is the problem of a single Prolog program acting as a server for multiple WWW clients. This issue is important as AI applications are normally large and slow to start up, so having a separate copy of the application running for each request may not be a viable solution.
Handling multiple clients means that multiple threads of control have to be handled in a single Prolog program. Having explored several approaches to this problem, in the case of EMRM, we found that achieving this goal in a traditional sequential Prolog implementation requires serious changes in the formulation of expert system rules, which results in losing the clarity of the original knowledge base. On the other hand we found that an or-parallel Prolog implementation can be used to provide the functionality of serving multiple clients, while keeping the knowledge base intact and preserving the declarative style of knowledge representation.
In the following we briefly outline the main functions of the EMRM and describe the major steps in transforming its user interface into HTML. We then discuss the problems stemming from the asynchronous nature of HTML communication, for both the single client and multiple client versions. Finally we outline a solution for asynchronous handling of multiple clients using an or-parallel Prolog implementation.
EMRM is designed to help physicians to get as much relevant information about their patient as possible before meeting the patient personally. While waiting for the doctor the patient can give information to a medical assistant who is supported by EMRM. Some of the questions are generated on the basis of the information already collected about the patient, and the medical knowledge incorporated in the knowledge base of EMRM. The answers of the patient are stored using the relevant medical terms of SNOMED [12], a medical thesaurus of over 40,000 terms. The physician gets the collected data and the possible diagnoses suggested by EMRM before meeting the patient. He can then collect further information by examining the patient and checking for further symptoms. These data, the diagnoses and the further diagnostic and therapeutic steps, are entered into the EMRM system by the physician and again stored as relations built from SNOMED terms.
The Prolog implementation of EMRM thus consists of the following main parts:
EMRM is a relatively large program (requiring about 20 Mb memory in the present prototype phase).
In the process of transforming EMRM to a HTML interface we first implemented an HTML version of the SNOMED browser, an important component that allows the user to find the appropriate medical term by a combination of tree traversal and text search [10]. We then continued the transformation process for the main dialogue of EMRM, including data entry and the display of the results.
The HTML version of the EMRM server consists of the Prolog program, a WWW server and and a small CGI script that mediates between the Prolog program and the WWW server. The Prolog program is running as a separate server process on the WWW server computer. Because of the large program size and relatively slow startup time it is reasonable to have the Prolog program running all the time, rather than to start it up separately for each request.
In the Prolog program there is a main loop waiting for client requests on a socket from the WWW-server. The user interface of the Prolog program is based on ``lazy'' querying techniques. i.e. the user is asked for some information only when the deduction process requires this. The interaction with the user is done through forms that are dynamic HTML pages. Whenever the user is asked for some information through such a form, the system sends out the dynamic HTML page and waits for the answer. The evaluation of the Prolog program is then suspended until an answer from the client process arrives. Such a low level wait-loop is part of any program code that implements forms. By the nature of the application such form requests are embedded within the Prolog search tree generated by the medical rule-base.
The WWW server communicates with the Prolog program through the CGI script, that is invoked whenever there is some communication from the user interface side.
The first problem, due to the asynchronous nature of HTML communication, already arises in the case of a single client. An HTML page does not completely disappear after the user has answered the query on the page, as it normally remains available through the history function of the browser (Netscape, Internet Explorer, etc.). Thus, all the previous queries are there, and in principle the user can go back at any time, change and re-submit some of the earlier answers.
In our present implementation we forbid such re-submission requests. In principle, the backtracking ability of Prolog could be used to interpret such actions as requests to forget all information gathered since the original of the re-submitted HTML page, and to restart the search with a new answer to the query on that page.
This can be accomplished in a way similar to the implementation of the retry function available in most Prolog debuggers. This function relies on a choice point (such as created by repeat/0) being placed in front of each retry-point. The retry operation is then performed by doing a far-reaching cut (ancestor-cut), pruning all choice points up to the chosen retry-point and then failing the computation. This unwinds the Prolog stacks up to the required point and, because of the repeat, restarts the computation there.
For this approach to work, the program should not be altering the Prolog dynamic database, so that execution of the retried goal is restarted in the same setting as the original execution. As a possible exception to this rule, earlier answers could be stored in the database, and used as the default selections in the repeated queries.
The second, more serious problem arises when dealing with several clients. E.g. if we have two clients, it should be possible to process their answers in some interleaved way, following the relative timing of their answers. In other words, we can have two clients, in different stages of evaluation, both waiting for some user answer, and we should be able to continue the execution with whichever client answers earlier.
The simplest way to achieve this coroutining behaviour is by requiring that the program in question is formulated as a set of separate actions to be carried out in response to the arrival of an answer. Although such a set-up is easy to implement, in most cases it completely destroys the logic of the program. This is not only because communication between phases has to be done through the Prolog dynamic database (rather than logic variables), but more importantly because the original logical structure of the rule-base cannot be preserved.
We have considered several options for implementing the coroutining execution of an existing Prolog program, without requiring its reformulation:
A common drawback of these schemes is that they work properly only with deterministic code. As they all rely on chronological backtracking in a single stack regime, backtracking in one of the coroutined branches will lead to (unnecessary) backtracking over the interleaved execution steps of other branches.
As EMRM heavily relies on backtracking, we need a solution that allows independent backtracking in the coroutined branches.
A natural approach is to consider parallel Prolog systems. There are several approaches in this area which support independent exploration of multiple searches: or-parallel systems, such as Aurora; systems supporting independent and-parallelism, such as the &-Prolog system [8]; and systems with explicit control of parallelism, such as CSR Prolog [7], and BinProlog extensions [3].
As one of goals of the CUBIQ project was to examine the usability of or-parallel Prolog systems in expert system applications, it was natural for us to explore whether Aurora can be used to support multi-client EMRM execution.
Aurora [9] is an or-parallel implementation of full Prolog based on SICStus 0.6. In Aurora a number of workers (i.e. processes, normally running on separate processors of a multiprocessor computer) work together on exploring the search tree corresponding to the Prolog program. Aurora preserves sequential Prolog semantics, e.g. the side-effect predicates, such as the ones for input-output and dynamic database handling, are executed in exactly the same left-to-right order as in a sequential Prolog.
This section outlines how Aurora can be used to support the execution of
multiple independent copies of a Prolog program, which interact with remote
users through the WWW. It is crucial for this purpose that Aurora supports
non-synchronised execution of side-effect predicates, by providing so
called cavalier variants, written as cavalier(Pred):
cavalier(write(foo)).Cavalier predicates are executed immediately, without any synchronisation with other branches. A typical usage of such predicates is to display tracing information on how the parallel execution proceeds.
Cavalier predicates are executed atomically, i.e. if two competing branches reach a side-effect predicate affecting the same resource(*) simultaneously, then these predicates will be executed in some arbitrary order, one after the other. For example, if a sequence of terms is displayed by a cavalier format predicate, this sequence is guaranteed not to be intermixed with output coming from other branches of the Prolog search tree.
Aurora also allows the user to control which predicates can be executed in parallel, by appropriate declarations.
We now first present a general skeleton of a multi-client Prolog server (Figure 1) and then describe how the process spawning and communication primitives of the skeleton can be implemented in Aurora.
loop(Socket) :-
repeat,
next_event(Socket, Event),
process_event(Event),
fail.
process_event(session(S)) :-
spawn(run_session(S)).
process_event(answer(Req, Answer)) :-
out(Req, Answer).
query(Req, Answer) :-
in(Req, Answer).
The predicate loop in Figure 1 implements the (non-terminating) main loop of the multi-client server. The argument of loop represents the socket used for network communication. This predicate first waits for the next network event (in next_event), and then processes the event through process_event. An event can be a request to start a new session, represented by a Prolog term of form session(S). This is processed by spawning a fresh copy of the Prolog server program ( run_session).
When, applying the lazy querying technique, further input from the remote client is needed within a session, the Prolog code for the session has to call the query predicate of the above skeleton(*). A query has a unique request identifier ( Req) as its input argument, and when the answer arrives it instantiates its Answer output argument. The answer to the query is detected as an event of form answer(Req, Answer) in the main loop. Processing of this event requires communicating the answer to the session waiting for it, this communication is done through two procedures named following the Linda convention [6] as out(Req, Answer) (on the sender side, in the main loop) and in(Req, Answer) (at receiving end, in the Prolog session).
We now proceed to show how the primitives spawn, in and out can be implemented in Aurora. As a first step let us assume that all of the user program ( run_session) is declared to be sequential, i.e. parallelism is only used for implementing multiple execution of Prolog sessions.
:- parallel spawn/1.
spawn(Goal) :-
( true
; call(Goal) -> fail
).
in(Req, Answer) :-
repeat,
cavalier(retract(request(Req,Answer))),
!.
out(Req, Answer) :-
cavalier(assert(request(Req,Answer))).
Figure 2 shows a simple implementation of the communication primitives. Spawning is achieved by simply opening a parallel choice with two alternatives: the first one is empty, thus returns to the callee immediately, while the second one calls the goal to be spawned. The Aurora parallel scheduler ensures that such a new parallel alternative is executed by an idle worker, if one exists. Note that this approach does not require the forking of a new process for each spawn operation: Aurora uses a fixed number of workers (processes), which are scheduled to execute tasks as they arrive (and sleep if there are no tasks to execute).
In this implementation, the communication between the main loop and the spawned processes is implemented using a dynamic predicate, request/2, as an application of general techniques described in [14]. The in/2 predicate spins in a busy waiting loop until the out/2 asserts the requested answer. The assert and retract predicates have to be cavalier, so that they are executed irrespectively of their position in the Prolog or-tree.
The solution for process communication presented in Figure 2 has several drawbacks. First, workers wait in a busy loop, thus wasting computing resources. This problem could be overcome by inserting a Unix sleep in the loop, thus making the processor available for other computations. This solution, however, still does not make the or-parallel scheduler aware of the fact that the execution branch in question is suspended. As the Aurora system can be started up with a fixed number of workers, say N, this means that at most N-1 sessions can be alive at any moment (one worker is executing the main loop).
As a fairly recent development, new primitives have been introduced in Aurora for user-controlled suspension and resumption of execution branches [2]:
Forces the current branch to suspend, and assigns it the label L. Labels currently can only be integers.
This marks the suspended branch labeled L as resumable and continues with the current branch. The scheduler may schedule a worker to restart the suspended branch any time after this resumption operation has been executed.
The new features make it possible to avoid the busy waiting in process communication.
in(Req, Answer) :-
force_suspend(Req),
cavalier(retract(request(Req,Answer))).
out(Req, Answer) :-
cavalier(assert(request(Req,Answer))),
resume_forced_suspend(Req).
Figure 3 shows the implementation of in and out with the new primitives. This approach does notify the Aurora scheduler about the branch becoming suspended and makes it possible for the scheduler to use the worker for executing code at other parts of the search tree. Consequently, it allows Aurora to be run with two workers only and still serve any number of requests, with interleaved execution. Since one of the workers is waiting for network input most of the time, we believe that such a two-worker Aurora configuration can be safely run on a mono-processor computer as well.
On the other hand, if a multiprocessor is available as a server, there is no need to forbid the exploitation of parallelism in the Prolog programs run. The Aurora scheduler will ensure that parallelism is exploited both between the independent threads of execution and within such threads.
We have implemented the single-client version of EMRM. Figure 4 presents a Web page with the start-up query of EMRM. We have designed the support for multi-client execution of Prolog servers and tested the first version of process communication primitives on simple examples.
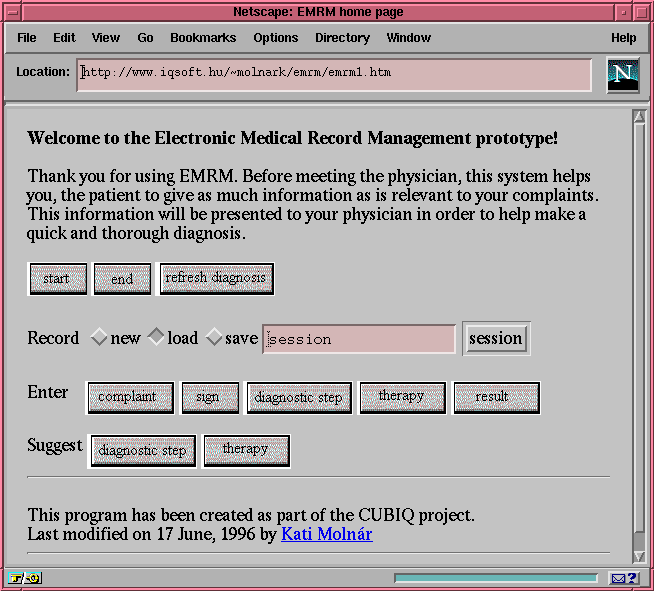
We plan to continue the development of the multi-client version of EMRM. We also hope to compare our method with approaches based on other parallel Prolog systems, such as &-Prolog and parallel BinProlog.
We have outlined EMRM, a Prolog application implementing a medical record management expert system. We have described our work on transforming the user interface of EMRM to apply a WWW browser communicating with the Prolog program through HTML forms and HTML pages.
We have outlined some techniques for interleaved execution of multiple copies of a server application in Prolog. We have pointed out that most of these are not capable of supporting the proper interleaving of multiple backtracking searches.
We have presented our design for a single Prolog server, based on an or-parallel implementation Aurora, supporting multiple clients with full support for independent Prolog search. The main advantage of this approach over running a separate copy of the application for each client is the avoidance of lengthy start-up time and significant reduction in memory requirements. As a further advantage the single server approach allows easy communication between the program instances serving the different clients, which may be useful e.g. for caching certain common results, collecting statistics, etc. An important aspect is that the knowledge base does not need to be changed and the commonly used lazy querying techniques can be safely applied.
We hope to complete the development of the multi-client version of EMRM in the near future. We believe this server will be able to serve several clients simultaneously, at a reasonable speed and with reasonable resources.
The authors are indebted to all their colleagues in the CUBIQ project and gratefully acknowledge the support of the European Union Copernicus programme, under project CP93-10979 `CUBIQ'.