A Calendar of Events - Architecture and Experiences
Stefan Lüttringhaus-Kappel and Dirk Schulz
Institut für Informatik III, Universität Bonn, Germany
E-mail: {stefan,schulz}@uran.informatik.uni-bonn.de
July 26, 1996
Institut für Informatik III, Universität Bonn, Germany
E-mail: {stefan,schulz}@uran.informatik.uni-bonn.de
July 26, 1996
Abstract:
The traditional media for such announcements are the department's bulletin board and the distribution of printed lists and invitations through internal mail. This is reflected in modern electronic media; the World Wide Web (WWW) pages are the bulletin boards -- you have to go there and watch, while email reaches you more directly and (hopefully) just in time.
A discussion of the requirements of an electronic calendar of events for our department revealed that we would need all of the media mentioned above: paper, WWW, and email. The role of the WWW is to show announcements as soon as they become available, the printed lists on the bulletin board serve their traditional purpose for those without the time to use the internet :-), and an email message reminds people about today's talks.
So far for those who seek information. Considering acceptance on the side of the provider of information, e. g. a seminar chairperson or a faculty secretary, it is important that no additional effort is required for maintaining the new information sources, i. e. all output, paper and paperless, must be derived from a single database. Moreover, to avoid any bottlenecks, it is absolutely necessary to have a decentralised administration of the various series of lectures.
In this paper we describe the architecture of a Prolog based information system which has been developed with the above requirements and constraints in mind. We also discuss the experiences made with certain approaches and tools during this design process.
attributes(root, wpermission, list). attributes(root, talktablehead, template). attributes(root, talktablebody, template). attributes(root, talktablefoot, template). ... attributes(root, talkreminder, template). attributes(institution, director, text). attributes(institution, latexpreamble, text). ... attributes(institution,X,T) :- attributes(root,X,T). attributes(seminar, headline, text). attributes(seminar, location, text). attributes(seminar, time, time). attributes(seminar, chair, text). ... attributes(seminar,X,T) :- attributes(institution,X,T). attributes(talk, author, text). attributes(talk, subject, text). attributes(talk, abstract, text). attributes(talk, date, date). ... attributes(talk,X,T) :- attributes(seminar,X,T). % Inheritance Types inherit_type(comment, X) :- !, X = none. ... inherit_type(wpermission, X) :- !, X = append. inherit_type(remindemail, X) :- !, X = append. inherit_type(_, copy).
In this section we describe the data model, the database, and transactions both through the email and the WWW interface.
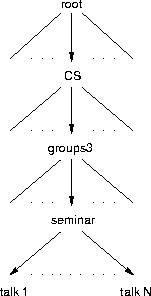
rootrestricts parent relationships in the database tree; talks are always leaves, talks are children of seminars, seminars are children of institutions or of the root (institutions are optional), and the special root node containing general settings resides always at the top.institution
institution
Attributes are
inherited along this hierarchy in an object oriented style.
Each level adds its own attributes (some are shown in figure
2), together with the appropriate data types.
In addition to the usual data types, Announce requires a
date and a time data type, both supporting
free format entry, canonical internal
representation, e. g. date(1996,6,14), and canonical output format.
There are several types of inheritance, including
inherit_type/2 (also in figure 2).
The method copy is the default, as this
is the most frequently used method.
The inheritance mechanism is implemented in Prolog, using only a few
more clauses. It is easy to extend and/or modify this mechanism to
match the requirements of future applications derived from the current
Announce system.
Originally, transactions could be initiated by email only, so we defined a simple markup language to describe transactions. We introduce the major concepts by example.
[command]create talk postersets in poster[/command] [date]4.9.96[/date] [subject]Applications of Efficient Lazy Set Expression[/subject] [author]Stefan L"uttringham-Kappel and Dirk Schulz[/author] [abstract] We add more expresive power to Prolog in the form of lazily evaluable set expressions. The need for lazy set expressions arise from the design of integrated logic+functional programming languages. ... [/abstract]
In figure 3 a talk is
inserted into the database by creating a new node.
Updates work similarly (update instead of create),
moreover it is sufficient to send only the values of attributes to be modified.
To receive the contents of node InfIII (an institution)
by email, we send the command
[command]submit node InfIII in root[/command]The answer is in the format of an update command, so we may edit it and send it back in order to update the database:
To: stefan@uran.informatik.uni-bonn.de Subject: VKAL-Query [command]update institution InfIII in root[/command] [seminarhead] <HTML> <HEAD><TITLE>Universitaet Bonn, Institut fuer Informatik III, Seminare <!--#include virtual="/inc/header-III.shtml3" --> <CENTER> <H2> Seminare und andere regelmäßige Vortragsreihen </H2> </CENTER> <DL> [/seminarhead] ... [institut]Institut f"ur Informatik III[/institut] [latexsubstyle]inf3[/latexsubstyle]

To receive a LaTeX file of a talk or a seminar, respectively, we say
[command]submit announcement postersets in posters[/command]or
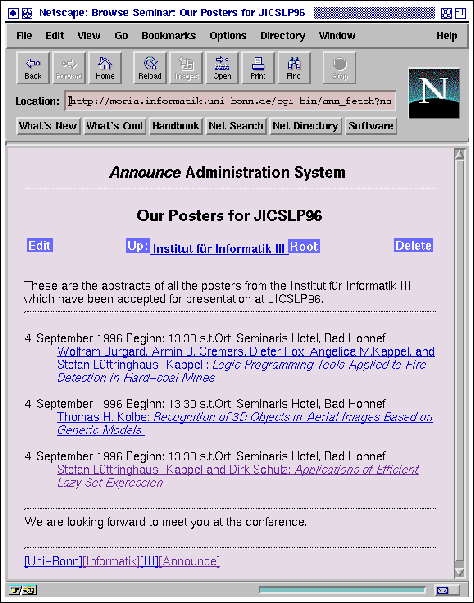
[command]submit announcement posters in InfIII[/command]The LaTeXed result of the latter is shown in figure 4.
Transaction processing is completely done in Prolog. Update transactions modifying the database used to trigger the generation of prefabricated pages in the previous Announce system. It is no longer necessary in the new approach, because pages are generated on the fly.
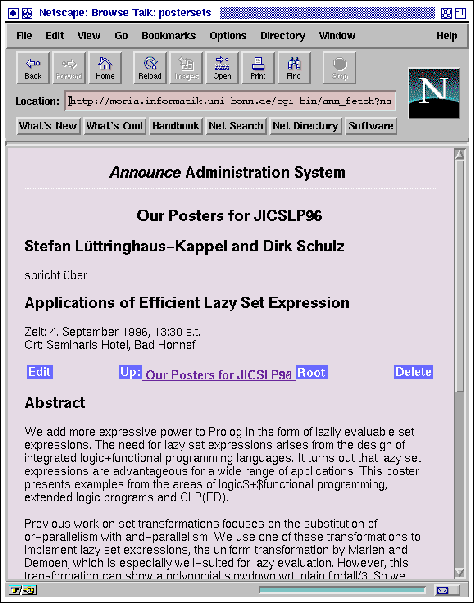
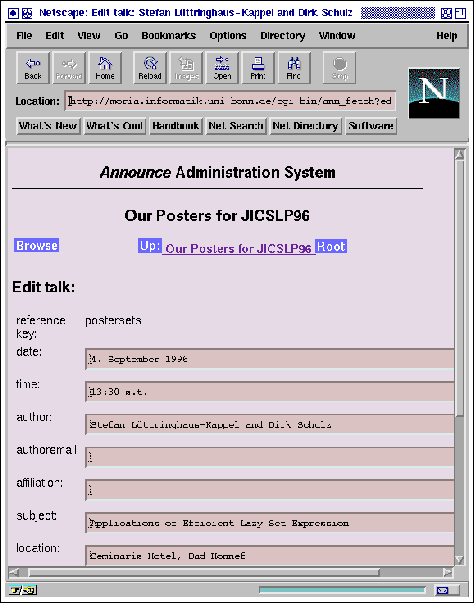
The tree structure of the database is reflected in a tree of hyper-linked Web pages in an obvious way. In the update mode, we distinguish navigation pages (figures 5 and 6), which are used to reach the node to be updated, and edit masks (figure 7). For each node there is a navigation page and an edit mask.
Submitting the contents of an edit mask immediately updates the database; the changes are reflected in all future requests to the Announce system.
The Announce system uses templates for output documents; the templates are ordinary attributes of the respective node types. We are going to briefly discuss two aspects of the template system. First, we give an example of the substitution mechanism used to fill in the variables of a template. Template parsing and substitution is done with a Prolog DCG.
%! if %abstract% == %!!%
then
%!<I>%subject%</I>!%
else
%!<A HREF="http:~announce/abstracts/%node%.html">
<I>%subject%</I></A> !%
The syntax, which appears to be a little bit ugly on first sight, was
designed to be distinguishable both in HTML and LaTeX source text.
%attribute% inserts the value of an attribute,
while %!...!% act as parentheses for more complex constructs.
Second, there are two types of documents wrt. the template system.
A talk page, for example, uses a single template describing the whole
page.
On the other hand, seminar pages contain a whole collection of
references to talks, requiring templates consisting of three parts:
the top, the iterated part, and the bottom.
LaTeX documents, for example, are generated from the template
attributes
latextalktablehead,
latextalktablebody, and
latextalktablefoot.
Similar attributes sets exist for HTML and ASCII (email) seminar pages.

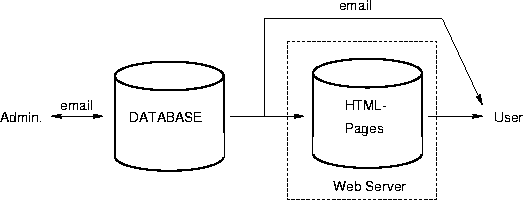
The ECLiPSe process loads the database file (about 250 kBytes) and either sends back the appropriate email message or updates the database and all affected HTML-pages, and rewrites the database file. This being a quite conservative approach, it has a couple of advantages nevertheless:
Finally, the distribution of email reminders is delegated to the Majordomo system [2], which is in use on the departmental server anyway.
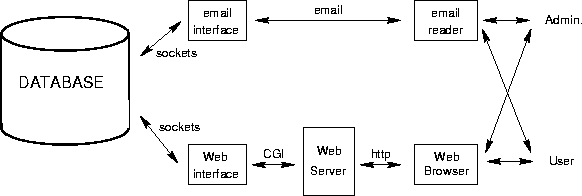
Writing email messages with all that markup appeared more and more cumbersome to the users of the announce system. So recently we extended the Announce system to allow updates through a WWW interface. The pages required for navigating through the tree to the node to be updated are created on the fly, as well as the input form containing the current values of the node.
Obviously, this approach is not restricted to the update mode; we now consistently generate all HTML pages dynamically, for both retrievals and updates. Prefabricated pages are no longer stored on the file system (figure 9).
The database is kept in an permanently running ECLiPSe process which is listening on a socket. Each request from the WWW client for a node is passed to this `database server' process via a very small CGI script (written in Perl). Database update requests are performed in the database server for immediate visibility of the results. In order to achieve persistence, the database state is saved to disk after each update transaction.
In both evolution steps of the announce systems we used ECLiPSe also
to generate HTML code. The previous system was based on templates (see
section 2.3.2 above) supported by a relatively simple
substitution mechanism. We decided to use
html_pl by D. Cabeza and M. Hermenegildo [1] in
an evaluation prototype of the
new system. html_pl allows structural representation and
structural manipulation of
HTML code as Prolog terms.
As outlined below, however, it turned out that using a text-based
substitution mechanism is preferable for our purposes; so we do not
really need structural manipulation of HTML code.
Our experiments in the Announce project and even more in a number of other projects leads to the statement, that HTML code is best generated from HTML template files prepared by an ordinary text editor. Having used various more or less simple substitution schemes in these projects, a substitution language summarising all our experiences is under development and will soon enter the test stage.
Prolog deals with database objects (Prolog terms) appropriately, unification being an adequate powerful mechanism, but a quite different situation arises for textual representation, e. g. Web pages. When it comes to string processing, scripting languages like Perl [6] with powerful string manipulation features and textprocessing functionality easily beat Prolog's string built-ins. Perl is both very powerful at text manipulation and almost complete wrt. system access; so its widespread use in CGI programming is not surprising at all. Note that we are not talking about formal or natural language parsing here; rather think of character set conversion, stripping white space, and regular expression substitution, and so on.
As a result of these observations, our Announce systems uses both Eclipse and Perl quite happily, each in the domain where it is strongest.
The way these systems connect the database to the Web is comparable to our approach, i. e. a traditional client/server design. A different approach is to bring query processing directly into the WWW client. This method is used by S. W. Loke and A. Davison [4]; they integrate Prolog into a WWW-Browser. The user has the opportunity to combine Prolog databases from several places and query results are displayed as HTML pages.
Due to our recent extensions the whole functionality of the system is provided through the Web interface. There is no need to learn a query language any longer, which greatly improves acceptance by the users.
Other options for future developments include:
https://cliplab.org/miscdocs/html_pl/html_pl.html.
ftp://ftp.greatcircle.com/pub/majordomo/.
http://www.odi.com/products/onweb/oforms.html.
http://www.cs.unc.edu/~barman/HT96/P14/lpwww.html.
http://www.ecrc.de/research/projects/eclipse.
http://www.perl.com/perl/info/documentation.html.