A Gentle Introduction to Amos
The world of Free/Libre Open Source Software (FLOSS for short) has seen a growth that is unbelievable just a few years ago. When the popular FreshMeat.net site was launched, there were just a few updates per day. Now, usually there are more than 50 new software announcements per day, and this represents just a small percentage of the true number - just consider SourceForge and its more than 60.000 projects, of which a large number are at the "beta" or better stage, or all the specialized software packages developed in the scientific and research communities.
As much as it seems a wonderful thing, it is becoming a problem in itself just finding what you are looking for - not only for users, but especially for developers and system integrators that may be willing to cooperate with an existing project, rather than starting something new from scratch. This is especially complex when someone wants to search for specific capabilities that may be embedded in a package, but that are not apparent from the documentation (that may be nonexistent to start with). And if it is a problem now, imagine what will happen in a few years, if the growth in FLOSS software production continues at this pace!
As members of the IST-sponsored AMOS project, we are trying to devise a potential solution to the search problem, through the development of a specialized search engine devoted to searching software code and other code-related artifacts (like code snippets, test cases and such). We are trying to combine several technologies to improve on existing techniques:
we are using a sophisticated, extremely efficient Prolog environment (called Ciao Prolog, and itself released under the GPL) to be able to perform complex manipulation of symbols,
the search engine itself is using a structured approach to representing software packages and their relationships, in the form of a very simple "ontology" and a dictionary of potential search terms, and
the algorithm used makes it possible to search for "assemblies", or set of packages that together try to match the user's requirements as closely as possible.
We will try to explain everything in a question-and-answer way. Stay with us!
Because searching isn't that simple. Let me make a small example: suppose that you want to find a way for creating a UDF filesystem for pressing a DVD. Let us try to find it with FreshMeat:
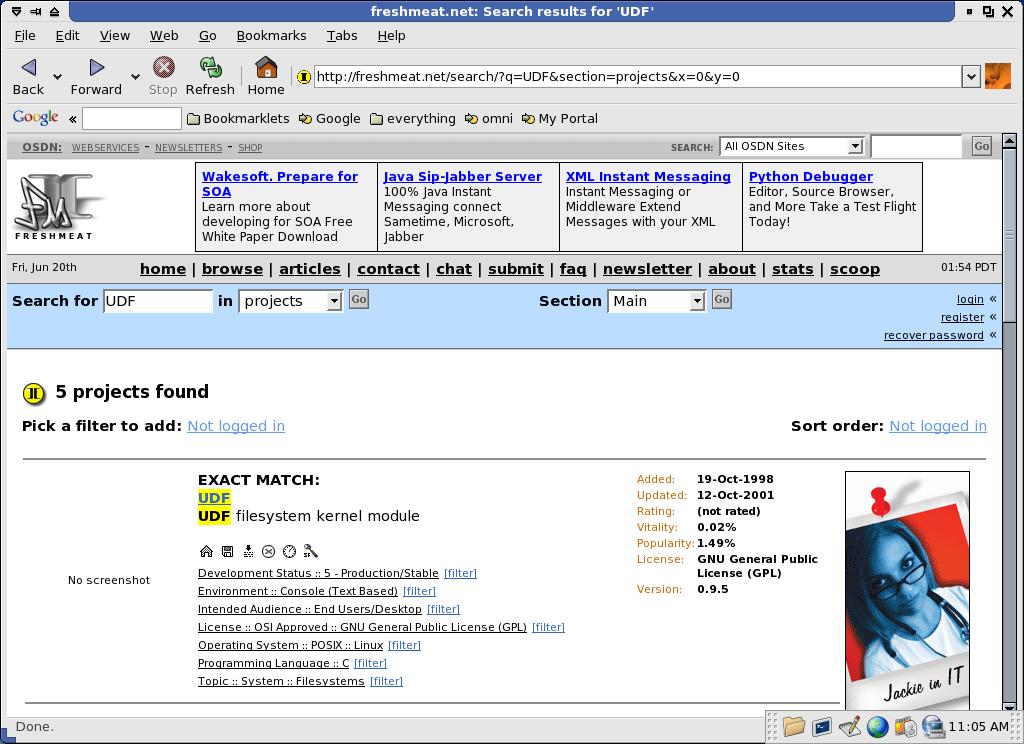
But we want to create the image, not read it. The others are not much better:
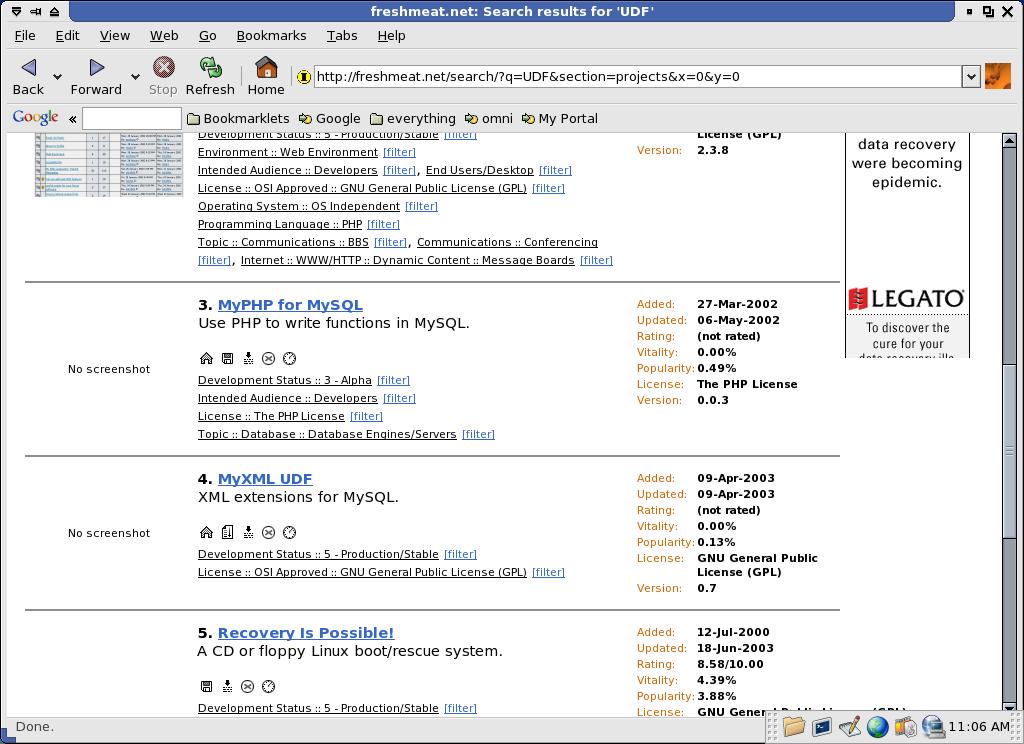
And Google?
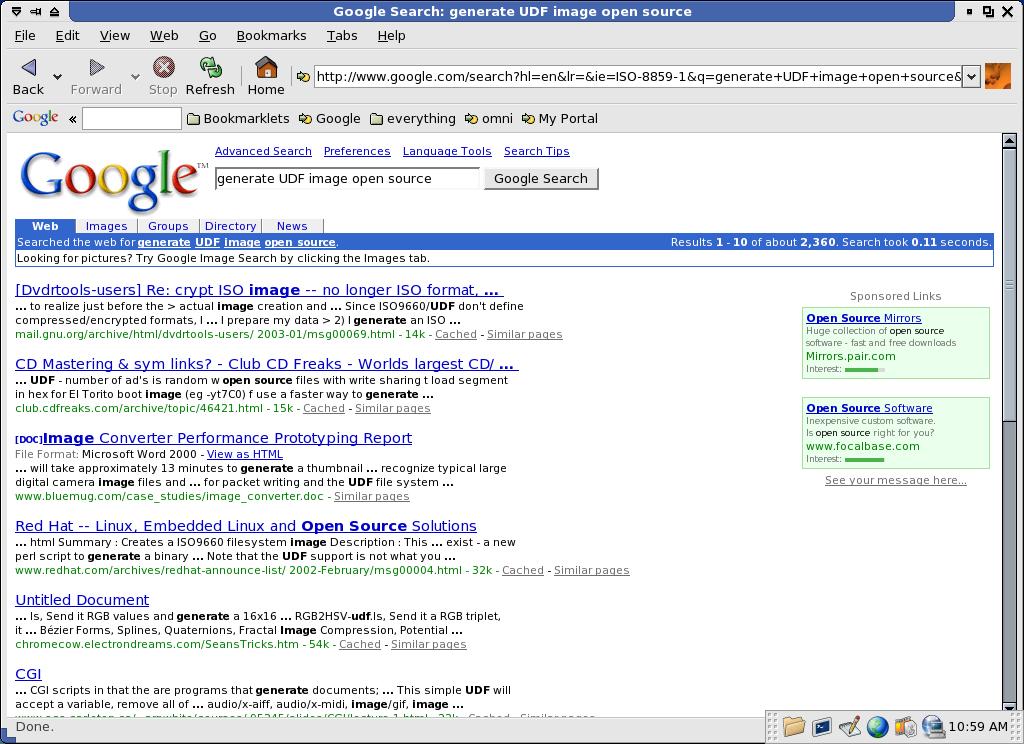
If you know where to look, you can find the right project (that is on sourceforge, and is called dvd-create). Of course, this is just an example- if we look for a LaTeX-to-PDF converter, for example, Freshmeat returns sensible answers at the 15th and 16th place, while google fares much better. More complex examples are much more difficult to search for; even more so in specialized areas where word meaning can be different.
We try to improve the situation by describing packages through their capabilities. That is, we are introducing a set of words (called "dictionary") and using those to describe what the package do. The AMOS search engine is also capable of combining packages together; let me make another example: suppose you want to find a way for converting LaTeX to PDF. You can do it in one sweep, or converting latex to postscript and the postscript to pdf, or using other intermediate formats. AMOS tries to find all suitable chain of packages, and creates "assemblies" that implements (if possible) what is requested.
We have tested the engine, by loading all the package descriptions of a RedHat distibution, and using the dependencies as capabilities. This test used 700 package descriptions and around 90000 relationships (dependencies) among them, with a dictionary of some 14000 terms (much more than we expect in a real database to have). This should give a reasonable approximation of the kind of load that may end up having. On a fairly standard PC quite complex queries with all the data stored in a relational database give back results in a few milliseconds (faster than RPM, taking into account that dependencies are used recursively). More detailed information, including detailed figures, can be found in the technical report The Matching Engine Design.
One general reason for this speed
is the use of a technique termed inverted indexes, which, so
to speak, precomputes part of the search work. This has been
classically used in relational databases, and is also in the heart of
the Google web search tool.
The Ciao prolog system is already open source software. The AMOS engine is also distributed under the GPL, and the database and tool information that will be filled up will be under the Free Documentation License (FDL).
Modern Prolog compilers (Ciao Prolog among them) are extremely efficient, and Prolog data structures are perfectly suited for the task at hand. Also, the declarative nature of Prolog maps extremely well to our algorithm, and there are several nice libraries for generation of web pages and interfacing with databases. If you really, really want it, the Ciao compiler can output C as its target, so you can have C if you really want (not that it's much readable, and it will not give you more capabilities than the Prolog system itself.)
No. As a direct inheritance from Ciao Prolog, the engine can be called from Java and C, and more interfaces are on their way.
XML is nice as a representation language; it is quite easy to take the database engine dump (that is, the full content of the database) and output XML. Reasoning over XML is still a difficult problem, expecially in terms of efficiency when the XML tree is huge. So, we prefer to do all the reasoning and the internal representation in the Ciao internal format, and leave to output plugins the task of converting to-from other formats.
First, a little introduction on the dictionary and the ontology (which, in our case, is just a different way of calling a tree containing all the relations between packages and the words that describe them). The dictionary is a long list, containing many different "words", or dictionary atoms. For example, "image_blurring" may be a suitable "word" (even if it is composed by two english words). To a dictionary atom we can also attach several synonims, and one generalization- for example, you can generalize "SQL database" into "database". This is used by the engine when no possible match is found, and generalization are used to try to find an approximate solution. The dictionary list is quite important in AMOS, and most of the effort in adding packages to the search engine is really related to finding the best "words" for describing packages. It is also quite important that the words that are added are not already in, thus leading to what we call "dictionary pollution".
A fundamental point of our project is the fact that the dictionary stays manageable, that is that it does not grow too much. All searches in AMOS are done only through words that are in the dictionary. You can freely use them in the search row, or use the boxes and select among them (eventually using the CTRL and shift keys to perform multiple selections), but you can't perform a free-text search (it will be no different from Google, in that case).
So, it is important to maintain the dictionary size to a minimum, because people performing the search will be forced to sift through the list, at least in the beginning.
By having an administrative interface, that allows for our reviewers to decide if the words are adequate, and eventually suggest alternatives. This administrative work is part of the project, and after the end of the contract we plan to give this administrative task also to the community. We will maintain to our best the system for at least 2 years after the end of the contract, providing connectivity and machines for that, and we hope to be able to donate at least a person to continue the maintenance work. We hope that the system will be adopted, and will be happy to help anyone that wants to deploy it. Everything contributed will be under the FDL, and periodically we will provide dumps of it for download.
When you fill in a package, you simply submit it through the web interface. It is then saved in a temporary database, and reviewed for consistency; the reviewer can propose modification, that are sent back to the submitter through email (including comments). When the reviewer gets back to the submission page, she gets back all the filled fields and the comments, and can change it at will and resubmit. If it is accepted, it gets immediately into the database, and can be immediately searched.
If we see that the need for modifications remains small, in the end we can opt for a no-administration system, and simply let the people enter packages directly into the database. This decision will be left for the end of the project, probably. Of course, the source is there - if you want, you can install your own AMOS!