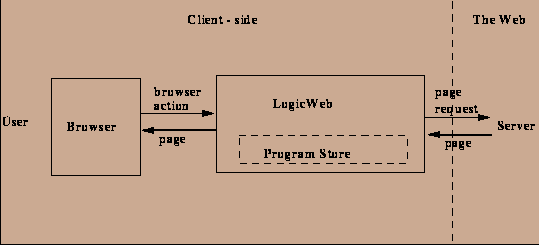
Figure 1: The LogicWeb system between the user and the Web.
Seng Wai Loke Andrew Davison
Department of Computer Science
University of Melbourne
Parkville, Victoria 3052, Australia
E-mail: swloke@cs.mu.oz.au
Department of Computer Engineering
Prince of Songkla University
Hat Yai, Songkhla 90112, Thailand
E-mail: ad@ratree.psu.ac.th
We propose a two-level model for the World Wide Web: Web pages are stored at the first level, and the links between them pass through a link abstraction layer. This extra layer permits processing to be carried out as part of link traversal, thereby increasing the expressiveness of links beyond direct connection between pages. This mechanism is implemented using LogicWeb, which allows Web pages to be treated as logic programs. One advantage of LogicWeb is that it enables conceptual Web structures to be coded in the abstraction layer which are amenable to sophisticated querying and automated reasoning. Another benefit is that it allows the easy specification of rules which model the nondeterministic and unpredictable nature of link activation in the Web.
Figure 1: The LogicWeb system between the user and the Web.
A prototype LogicWeb system has been implemented using the NCSA XMosaic Browser, C, and Prolog [6,8], and was used as a testbed for the examples in this paper. When a Web page is retrieved, it is displayed by the browser as normally. However, LogicWeb also translates all retrieved pages into programs. The basic transformation generates two facts for each Web page:
my_id("URL").
h_text("Page text").
my_id/1 holds the program's own ID which is its URL, while
h_text/1 contains the complete text of the Web page
(including its HTML tags) as a string.
The system parses each page looking for
link information so that a link/2 predicate can be
generated. For instance, the anchor in the line:
like <A HREF="http://www.prost.org/beermake.html">beer making</A>.becomes:
link("beer making", "http://www.prost.org/beermake.html").
The system stores meta-level page information supplied by the Web server
in about/2 facts. Typically, this
information includes the MIME (Multipurpose Internet Mail Extension)
version, the server version, the page request date, the content type,
the content length, and the time the page was last modified.
For instance, the about/2 fact for the last modified time of
a page would be:
about(last_modified, "Sunday, 08-Dec-96 20:48:29 GMT").Facts about the page structure can also be generated when required, including a title/1 fact and similar information about section, sub-section, and other headings. LogicWeb code is included in a Web page inside a ``<LW_CODE>...</LW_CODE>'' container. The language utilised by LogicWeb is a fairly elementary Edinburgh-style Prolog with some additional operators. The main new operator applies a goal to a program specified by a Web request method and its program ID (i.e. its URL):
lw(RequestMethod, URL)#>Goal.RequestMethod refers to the underlying Web communication protocol, HTTP [1]. The HTTP methods currently supported by LogicWeb are HEAD, GET, and POST. The HEAD method retrieves meta-level information about a page, whereas the GET and POST methods retrieve both meta-level information and page contents. A GET request only sends the URL of the required page, while a POST request can send arbitrary data in addition to the URL. At the LogicWeb level, these three methods are identified by the RequestMethod terms head, get, and post(Data). Each of the methods retrieves a Web page, which is stored in the LogicWeb system as a logic program. Once the logic program has been created, the #>/2 goal is applied to it. Consequently, the lw/2 term can be viewed as a specification of the logic program to which the goal is applied. The behaviour of the #> operator is actually more complex, in that the logic program defined by the lw/2 term is only retrieved if it is not already present in the LogicWeb store (see Figure 1). If the program is present then the goal is applied to it, without the need for code to be brought over the Web. The following example shows how LogicWeb predicates can be used to describe research interests in a home page:
<HTML>
<HEAD>
<TITLE>Seng Wai Loke</TITLE>
</HEAD>
<BODY>
<H1>Seng Wai Loke's Home Page</H1>
...
<!--
<LW_CODE>
interests(["Logic Programming", "AI", "Web", "Agents"]).
friend_home_page("http://www.cs.mu.oz.au/~friend1").
friend_home_page("http://www.cs.mu.oz.au/~friend2").
interested_in(X) :-
interests(Is), member(X, Is).
interested_in(X) :-
friend_home_page(URL),
lw(get,URL)#>interested_in(X).
</LW_CODE>
-->
</BODY>
</HTML>
The code appears inside a ``<!--...-->'' container so that it is
uninterpreted by the browser.
interested_in/1 states that the author is interested in several
topics and in what his friends are interested in. The ``#>''
goal in the second clause of interested_in/1 evaluates the
goal interested_in/1 against each friend's home page.
Hidden from the user, each page is retrieved using
a GET method request, and transformed to a logic program before the
interested_in/1 goal is evaluated.
link_action/1 is an important built-in predicate, which is
automatically invoked when a link is selected on a page. The URL of the
link is passed as a string argument to the
link_action/1 call.
link_action/1's normal meaning is to retrieve the page, place its
program in the store, and display the page. However, it can be redefined
by including a link_action/1 predicate in the LogicWeb code part
of the page.
This mechanism means that arbitrary computation can be carried out in
response to link selection, and is the implementation basis of our
two-level Web model.
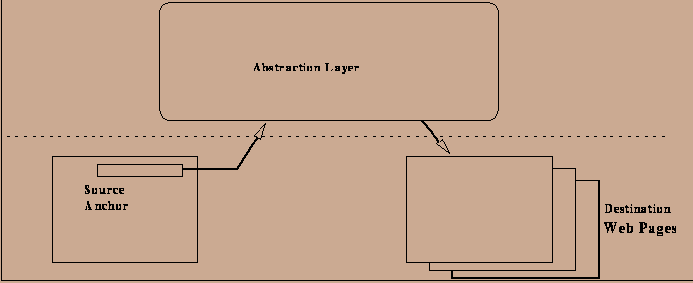
Figure 2: The two-level Web model. A link abstraction layer separates
the source and destination of links.
Links in the existing Web are uni-directional, have a fixed configuration, and go from one source page to one destination page. Links at the abstraction layer can be bi-directional, dynamically configured, and go from many sources to many destinations. The link abstraction layer can implement many link formalisms, and we contend that logic programming is particularly suitable for two key aspects:
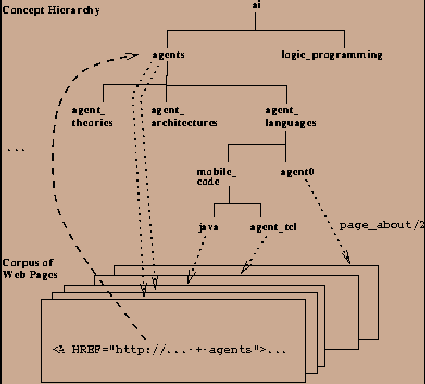
Figure 3: An IS-A hierarchy.
The dashed arrow shows a link referring to a
concept in the hierarchy. The dotted arrows show mappings
from concepts to Web pages as specified by page_about/2.
isa/2 represents an IS-A relation between concepts in the form of isa(Subconcept, Concept) links:
isa(logic_programming, ai). isa(agents, ai). isa(agent_theories, agents). isa(agent_architectures, agents). isa(agent_languages, agents). isa(mobile_code, agent_languages). isa(java, mobile_code). isa(agent_tcl, mobile_code). isa(agent0, agent_languages).To build an IS-A hierarchy, we define the transitive closure on isa/2:
trans_isa(Concept1, Concept2) :- isa(Concept1, Concept2). trans_isa(Concept1, Concept2) :- isa(Concept1, Mid), trans_isa(Mid, Concept2).We associate URLs with concepts using page_about/2:
page_about(agents, "http://machtig.kub.nl:2080/infolab/egon/Home/agents.html"). page_about(agents, "http://www.cs.mu.oz.au/~swloke/res1.html"). page_about(java, "http://java.sun.com/"). page_about(agent_tcl, "http://www.cs.dartmouth.edu/~agent/agenttcl.html"). page_about(agent0, "http://www.scs.ryerson.ca/~dgrimsha/courses/cps720/agent0.html"). :trans_about/2 defines a transitive version of page_about/2 which associates a concept with a URL if one of its sub-concepts is associated with that URL:
trans_about(Concept, URL) :- page_about(Concept, URL). trans_about(Concept, URL) :- trans_isa(SubConcept, Concept), page_about(SubConcept, URL).We assume that the complete IS-A structure is stored in the page:
http://www.cs.mu.oz.au/~swloke/link_kb.htmlAn IS-A query will be phrased as a syntactic extension of that page's URL:
http://www.cs.mu.oz.au/~swloke/link_kb.html-+-<concept-name>A URL of this type will be understood to mean: retrieve a page associated with that concept-name in the IS-A hierarchy. For example, a page about agents can be obtained by dereferencing:
http://www.cs.mu.oz.au/~swloke/link_kb.html-+-agentsThis behaviour is implemented by redefining the meaning of link_action/1. It must extract the concept from the string passed to it, search the IS-A hierarchy for a suitable URL, and then display that page:
link_action(URLstring) :- link_parts(URLstring, ISA-URL, Concept), lw(get, ISA-URL)#>page_about(Concept, ConceptURL), my_id(MyURL), ConceptURL \= MyURL, show_page(ConceptURL). link_parts(URLstring, ISA-URL, Concept) :- append(ISA-URL, [0'-,0'+,0'-|ConceptStr], URLstring), atom_chars(Concept, ConceptStr). show_page(URL) :- lw(get, URL)#>h_text(Src), display_page(URL, [data(Src)]).link_action/1 uses link_parts/3 to split the URL string into the URL for the IS-A hierarchy page and the concept. A suitable URL related to the concept is obtained by calling page_about/2, and the corresponding page is displayed with show_page/1 (but only if it is different from the current page).
By changing the meaning of link_action/1, the same link can have quite different semantics. For instance, all pages related to the given concept can be returned. link_action/1 uses setof/3 applied to trans_about/2 to obtain all suitable URLs. If only a single URL is found then show_page/1 is called, otherwise the list of URLs is assembled into a HTML page by report_urls/3 and printed.
link_action(URLstring) :-
link_parts(URLstring, ISA-URL, Concept),
setof(DestURL, lw(get, ISA-URL)#>trans_about(Concept, DestURL), DestURLs),
([DestURL1] = DestURLs ->
show_page(DestURL1)
;
report_urls(DestURLs, Concept, Links),
display_page("Multi-destination link", [data(Links)])
).
Figure 4 shows the page constructed when the link to ``agents''
is followed.
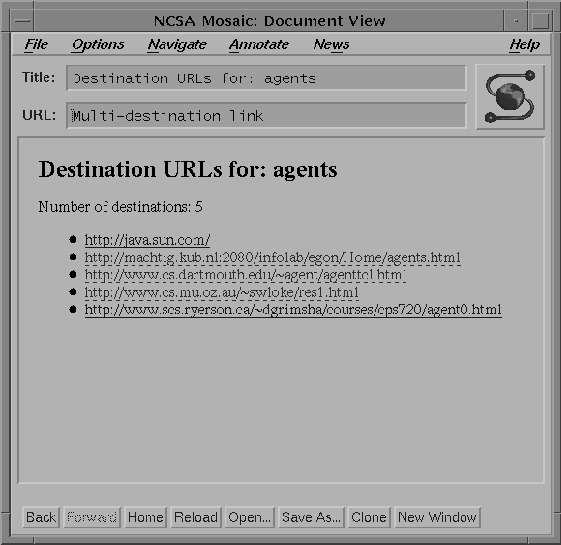
Figure 4: The page constructed when the link to ``agents'' is selected.
page_details(Name, URL)e.g.
page_details("Seng's_Page", "http://www.cs.mu.oz.au/~swloke").
page_details("Andrew's_Page", "http://fivedots.coe.psu.ac.th/~ad").
This database will be stored in a globally known Web page at:
http://www.db.com/details.htmlWe extend the URL syntax to include a page name reference:
http://www.db.com/details.html-$-Seng's_PageWhen such a URL is dereferenced on a page, we must define its meaning with link_action/1:
link_action(URLstring) :- append(DbURL, [0'-,0'$,0'-|PgName], URLstring), lw(get, DbURL)#>page_details(PgName, PgURL), show_page(PgURL).
The same technique can be used to simplify page referencing on a server. We assume that each server has a database called map.html of page_map/2 facts. The database maps page names to actual pages on the server. For example:
page_map("LogicWeb", "http://www.cs.mu.oz.au/~swloke/logicweb.html").
Users can employ a particular server's map.html database
by writing URLs of the form:
http://<server-address>/map.html-$-<page-name>e.g.
http://www.cs.mu.oz.au/map.html-$-LogicWebThis will return Seng Wai Loke's logicweb.html page. This mechanism not only simplifies the information required to retrieve a page, but can also be utilised as a redirection and page protection device.
link_action(URL) :- up_to_date(URL), interesting(URL), not(bookmarked(URL)), show_page(URL). up_to_date(URL) :- lw(head, URL)#>about(last_modified, LastModifiedTime), getime(LastModifiedTime, '1997;04;31;01:00'). interesting(URL) :- lw(get, URL)#>h_text(Src), lw(get, "http://www.cs.mu.oz.au/~swloke/")#>interested_in(Keyphrase), contains(Src, Keyphrase). bookmarked(URL) :- lw(get, "http://www.cs.mu.oz.au/~swloke/book_marks.html")#>link(_, URL).up_to_date/1 examines the page's meta-level information. getime/2 checks if the last modified time is equal to or after 1 am on the 31st of April 1997. interesting/1 assumes that Seng Wai Loke's home page contains an interested_in/1 predicate (as in section 2), and checks if any of its key phrases are in the text of the page. bookmarked/1 assumes the existence of a book_marks.html page which contains links to Loke's bookmarked pages. These are tested against the page being considered.
http://annotations.url.db/contains facts relating the URLs of pages to notes that must be added to the bottom of those pages. The facts are in the form:
annotation_page(URL, NotesURL).NotesURL is the URL of the page containing the notes about the URL page. For a given page, the following rule retrieves its notes and displays the page text followed by those notes:
link_action(URL) :-
lw(get, "http://annotations.url.db/")#>annotation_page(URL, NotesURL),
lw(get, URL)#>h_text(Src),
lw(get, NotesURL)#>h_text(Notes),
display_page("Annotated Page", [data(Src), data(Notes)]).
Customising Web pages
during link traversal is similar to an application of perspectives
in [12,13].
Perspectives are graph structures that can be combined and operated upon in
various ways. Applied to the Web, perspectives can represent
combinations of pages or page fragments.
link_action(URL) :-
(redirection_page(URL) ->
lw(get, URL)#>link(_, NewURL),
show_page(NewURL)
;
show_page(URL)
).
redirection_page(URL) :-
lw(get, URL)#>title(Title),
( contains(Title, "has moved")
; contains(Title, "site moved")
; contains(Title, "redirection to new location")
; contains(Title, "redirect URL")
).
A redirection page is recognised by looking for
specific phrases in the title.
link_action(URL) :-
(lw(get, URL)#>h_text(HTMLSrc) ->
display_page(URL, [data(HTMLSrc)])
;
mirrored_by(URL, MirrorURL),
show_page(MirrorURL)
).
We assume the existence of mirrored_by/2 facts which
store the mirror URLs for a site. This simple rule
can be modified in various ways, such as to also access a mirror
site when a request time-outs.
In the HyperBase hypertext tool [4,7], Prolog code can be invoked when buttons are pressed. Applications include a system to help users fill in forms, and a system for teaching neuropathology. Our work is similar in that we also invoke Prolog-like code, but this is in the context of the Web, and the manipulation of pages as logic programs.
The use of logic programming makes the development of knowledge-based structures in the link abstraction layer very straightforward. Also, the nondeterminism in logic programming is ideal for handling many aspects of the dynamic, rapidly changing nature of the Web.
Future work will investigate how to control the time and space resource usage of link computations. We are also looking into automatic means for building and maintaining knowledge-based structures like those described in §4.1.
The current LogicWeb implementation automatically stores a fixed subset of HTML tags in predicate form, but these are not always what are required by an application. The programmer must then resort to using the lower-level parsing utilities in LogicWeb to extract further information. We plan to make it easier to specify which page components should be automatically stored as facts as a page is downloaded.