Lightweight Deductive Databases on the World-Wide Web
S.W. Loke, A. Davison, and L. Sterling
Department of Computer Science
The University of Melbourne
Parkville, Victoria 3052, Australia
Email: {swloke,ad,leon}@cs.mu.oz.au
Department of Computer Science
The University of Melbourne
Parkville, Victoria 3052, Australia
Email: {swloke,ad,leon}@cs.mu.oz.au
Abstract:
Our aim is to enhance the Web with information which is more susceptible to sophisticated automated searching, extraction, and processing. Such information needs to be stored in a structured form, and be sufficiently high-level (or abstract) to be programmable, while remaining readable.
An interesting candidate as a representation formalism is logic programming [24]. Logic programming is based on mathematical logic, where computation is treated as deduction from a set of axioms or rules. Logic programming provides a uniform means for representing data and computations, is declarative (compared to imperative languages), and has a solid semantic basis. In addition, knowledge based query processing is possible with the aid of logic programming. For instance, we can represent concept hierarchies, and meta-level knowledge about databases.
Deductive databases extend relational databases, utilising logic programming rules for more complex data modelling [22]. A deductive database is, in essence, a logic program: base relations map to facts, and rules are used to define new relations in terms of base relations, and to process queries. Also, deductive databases structure information according to predefined conceptual schema. Hence, deductive databases qualify as an appropriate metaphor for information processing on the Web.
This paper investigates how deductive databases can be incorporated into Web pages. In the spirit of [11], we call these databases lightweight deductive databases, since our intention is to use the Web as a source of structured information, rather than to provide functionalities such as transaction processing and query optimisation.
Since lightweight deductive databases are distributed on the Web, they have the following features:
We base this work on LogicWeb [19], an integration of logic programming and the Web, which treats Web pages as logic programming modules. Meta-level rules on how LogicWeb modules can be accessed and combined are written as logic programs.
In the rest of the paper, we illustrate the above ideas, by considering lightweight deductive databases for citations. On-line citations are a valuable resource for bibliography entries, and for obtaining papers.
In the following, we assume that the reader is acquainted with Prolog. In §2, we introduce lightweight deductive databases, and give a brief overview of LogicWeb, followed by a simple lightweight deductive database example. In §3, we show how lightweight deductive databases can be combined and extended, and in §4, knowledge-based query processing is explored. In §5, we review related work, and compare existing deductive database systems with our lightweight counterpart. §6 concludes.
LogicWeb provides the framework for lightweight deductive databases. Below, we outline LogicWeb, and describe a lightweight deductive database of citations.
More importantly, a LogicWeb module can contain a logic program written in Prolog with some extensions. Among the extra operators are ones for invoking goals in other modules, and for combining modules together. A key element of these features is the use of terms of the form m_id(URL) to refer to modules, where URL is the URL of the module.
When a LogicWeb module is downloaded, its logic program, and any other information it might contain (written in ordinary HTML) are loaded into a Prolog environment. The ordinary HTML text is stored in a fact, and can be subsequently processed (e.g., links it contains can be extracted and stored in newly created facts, as mentioned above).
A LogicWeb module may contain a lightweight deductive database (or component thereof). In addition, it may include descriptions of the database (e.g., database schemata) written in ordinary HTML. In the rest of the paper, we shall use the term database modules to refer to LogicWeb modules containing lightweight deductive databases.
 . They are illustrated below.
. They are illustrated below.
Consider a lightweight deductive database of publication citations. A citation consists of distinct components (or attributes), and it should be possible to perform queries using these attributes. Also, it is convenient for citations to be separately stored and maintained (e.g., by the authors themselves). For these reasons, it is useful to store citations in structured databases, and to combine them only during query evaluation. A possible schema for citations is:
pub_cit(authors,title,pub_type,collection_name,web_location,date)
The schema describes the components of a typical publication citation: the names of the authors, the title of the paper (which is used as the primary key, indicated in bold), the type of the publication (e.g., conference, technical report, or journal), the collection in which the paper was published, the URL of an on-line version, and the date of publication.
An instance of the schema is:
pub_cit([author("Seng","Loke"),author("Andrew","Davison")],
"Logic Programming with the World-Wide Web",
conference,"Hypertext '96",
"http://www.cs.mu.oz.au/~swloke/papers/paper1.ps.gz",
date(march,1996)).
From a database of pub_cit/6 facts, a database of journal citations in 1996 can be formed, which conforms to the schema:
journal_1996_cit(authors,title,collection_name,month)
The new relation is derived using the rule:
journal_1996_cit(Authors,Title,CollectionName,Month) :-
pub_cit(Authors,Title,journal,CollectionName,_,date(Month,1996)).Rules can be written to process queries on the above databases. For example, the following rules find all the titles of papers by an author in a given year:
get_titles(Name,Year,Titles) :-
setof(Title,get_title(Name,Year,Title),Titles).
get_title(Name,Year,Title) :-
pub_cit(Authors,Title,_,_,_,date(_,Year)),
member(Name,Authors).A database module can be downloaded to a client system, and queried. Alternatively, the base relations (facts) can be stored in one module, and the query processing rules in another. These can be downloaded separately, and combined on the client-side.
In this section, we explore the use of virtual relations and relational joins. A virtual relation is formed from other database relations by a set of rules, all defining the same head predicate, but each using a different relation in its body. In a relational join, two relations are combined based on shared attribute values.
From structured logic programming [7], we appropriate the notions of context switching and the composition operations of union, and overriding union. By composing database modules, we effectively combine the databases in those modules.
Other ways of composing logic programs have been considered in the literature, such as intersection [5], retraction [6], and various forms of inheritance [7, 21]. Utilising a larger repertoire of operators allows more kinds of compositions to be expressed in queries, but increases complexity.
The LogicWeb goal, Module#>Goal, causes the evaluation of the logic programming Goal in the LogicWeb Module. Module is loaded the first time a goal requesting it is evaluated. Subsequent evaluations of goals in the module use the already loaded version. The same loading behaviour is employed by the other LogicWeb operators introduced below. The #> operator executes a goal using only the predicates in its prescribed module, excluding other modules.
In the following examples, we assume a database of technical report details with the schema:
tr_cit(authors,title,tr_number,web_location,date)
A virtual relation, cit/6, of citations can be defined in terms of technical report and publication details:
cit(Authors,Title,Type,BookName,WebLocation,Date) :-
pub_cit(Authors,Title,Type,BookName,WebLocation,Date).
cit(Authors,Title,technical_report,BookName,WebLocation,Date) :-
tr_cit(Authors,Title,BookName,WebLocation,Date).cit/6 assumes that pub_cit/6 and tr_cit/5 are present in the current module (i.e., the module containing the virtual relation). However, if they are stored in different modules, we can employ #> to retrieve them:
cit(Authors,Title,Type,BookName,WebLocation,Date) :-
location_of(publications,PubsURL),
m_id(PubsURL)#>pub_cit(Authors,Title,Type,BookName,WebLocation,Date).
cit(Authors,Title,technical_report,BookName,WebLocation,Date) :-
location_of(technical_reports,TRsURL),
m_id(TRsURL)#>tr_cit(Authors,Title,BookName,WebLocation,Date).
A derived relation of citations that are both technical reports and publications can be formed as follows:
pub_tr_cit(Authors,Title,PubWebLocation,TRWebLocation) :-
location_of(publications,PubsURL),
location_of(technical_reports,TRsURL),
m_id(PubsURL)#>pub_cit(Authors,Title,_,_,PubWebLocation,_),
m_id(TRsURL)#>tr_cit(Authors,Title,_,TRWebLocation,_).
The union of two LogicWeb modules corresponds to the set-theoretic union of the clauses in both modules [7]. Union is useful when a query is to be evaluated with respect to two or more modules. In LogicWeb, this is expressed using the lw_union/1 construct in a goal, such as:
lw_union(ListOfModules)#>GoalThis goal evaluates Goal in the union of the modules in ListOfModules.
We can use the following rule to retrieve citation authors from a union of databases:
authors(CitMod,Modules,Authors) :-
lw_union([CitMod|Modules])#>cit(Authors,_,_,_,_,_).
CitMod contains the original definition of cit/6 from §3.1. Modules is a list of modules, containing pub_cit/6 and tr_cit/5 facts. Citations are retrieved from the union of all the modules, treated as a single citation database. Hence, the term lw_union([CitMod|Modules]) represents a virtual citation database. If the modules are on different servers, they are retrieved before the cit/6 goal is evaluated. This behaviour allows the combined database to be spread across several servers.
In discussing the dynamic composition operations, we employ the notion of current context of a goal (or operation). This refers to the module, or the union of modules, in which the operation is evaluated. The dynamic composition operations compose a prescribed module with their current context, whereas the #> operation ignores its current context.
The following rule utilises the module m_id(AddressBookURL) which contains a predicate cit_db/2. cit_db/2 contains the database module URLs for every department. The module URL for a given department is retrieved, and the citation authors in that module are then retrieved.
authors(Department,AddressBookURL,Authors) :- m_id(AddressBookURL)#>cit_db(Department,CitationsModURL), m_id(CitationsModURL)>>cit(Authors,_,_,_,_,_).
Another use of dynamic union is to load modules containing utility predicates for processing queries. Dynamic union allows the utility predicates to call predicates in the current context.
m_id(CitationsModURL)@>cit(Authors,_,_,_,_,_)then the definition of cit/6 in the current context would momentarily be overridden by the definition of cit/6 in m_id(CitationsModURL).
Complex forms of query processing are possible with lightweight deductive databases. We demonstrate this with a longer example involving the logic programming encoding of the domain-specific information within Web pages, and knowledge about the structure of Web sites of a certain type. This information is used to guide automated search.
We assume that research in a Computer Science department is organised into sections. A section is divided into groups, and sections and groups are composed from projects. Each project consists of researchers. This follows the organisation of research in the Computer Science department at the University of Melbourne as of May 1996.
When describing the structure of a Web site, we use the notion of page types. Page types are names for sets of pages (some of which may contain only one page). They enable individual pages to be referred to by their types rather than by their URLs which would be too specific, and may change over time. Page types also allow collections of pages to be conveniently addressed. We utilise the following page types in our example: dept, research, project, project_members, and researcher. These page types will be used for describing our Web search strategies.
The Web structure for a Computer Science department is shown in Figure 1. The departmental home page (of type dept) has a link to a page (of type research) containing research information (in HTML). This information includes a description of the relationships between sections, groups, and projects, and links to pages describing projects (of type project). Each project page has a link to a page containing information about its members (of type project_members), and each project_members page has links to the members' home pages (which are of type researcher). The publication citations for each project are distributed (and separately maintained by authors) in database modules accessible from the home pages of the researchers.
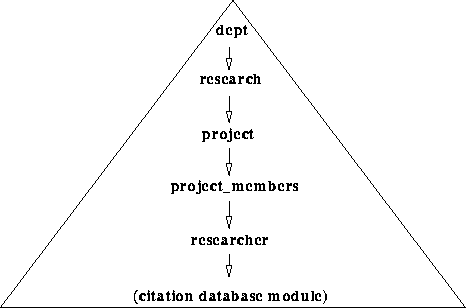
We wish to develop code to find all the citations for a given section. Two approaches are possible:
Finding database modules consists of two main steps:
In order to implement the above strategy, we need to formalise the relationships between sections, groups, and projects (to carry out (1)), and specify the Web structure (in order to do (2)).
To find the projects contained in a given section, we can parse the research page, and extract the required information. However, we would need to do that each time a query is processed. A more efficient alternative is to represent the knowledge on that page as logic programming facts and rules, and reason with them.
The relationships between sections, groups, and projects, are depicted as a hierarchy of concepts in Figure 2. This is a representative diagram; a typical department would have many more sections, groups, and projects.
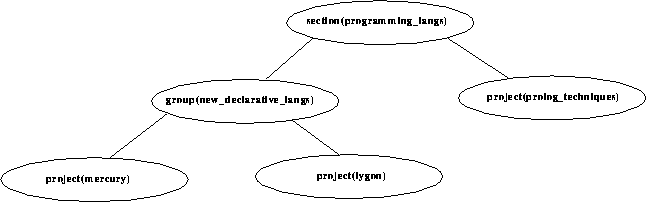
The relationships are represented using has_part/2 facts, which specifies how sections, groups, and projects are related. contains/2 defines the transitive closure of the has_part/2 relation.
has_part(section(programming_langs),group(new_declarative_langs)). has_part(group(new_declarative_langs),project(mercury)). has_part(group(new_declarative_langs),project(lygon)). has_part(section(programming_langs),project(prolog_techniques)). contains(X,Y) :- has_part(X,Y). contains(X,Z) :- has_part(X,Y), contains(Y,Z).
The sequence of page types in Figure 1 can be captured using precedes/2 facts:
precedes(dept,research). precedes(research,project). precedes(project,project_members). precedes(project_members,researcher).
A section name (e.g., ``Programming Languages'') can be selected by a user from a menu displayed by the browser. This is translated into a section/1 term, and a goal like the following is generated:
get_citations(section(programming_langs),Citations)Evaluation of the goal results in Citations being instantiated with a list of pub_cit/6 facts. These are formatted and displayed by the browser.
get_citations/2 uses the logic programming representation of the research information (contains/2 and has_part/2) to retrieve all projects belonging to the specified section, and then collects the citations from those projects:
get_citations(Section,Citations) :-
setof(project(Name),contains(Section,project(Name)),Projects),
collect_citations(Projects,Citations).The definition of collect_citations/2 is:
collect_citations(Projects,Citations) :-
location_of(dept,DeptURL),
setof(ModId,find_citmod(dept,DeptURL,Projects,ModId),ModIds),
retrieve_citations(ModIds,Citations). The initial call to find_citmod/4 in collect_citations/2 searches from the dept page until a researcher page is found. The database module URL on that page is then extracted by extract_modURL/2. find_citmod/4 makes use of a predicate next_link/5, which uses heuristics to determine the next link to follow on any page.
The definition of find_citmod/4 is as follows:
find_citmod(researcher,PageURL,_,m_id(CitationsModURL)) :-
extract_modURL(PageURL,CitationsModURL).
find_citmod(PageType,PageURL,Projects,CitationsModId) :-
next_link(PageType,PageURL,Projects,NextPageType,NextPageURL),
find_citmod(NextPageType,NextPageURL,Projects,CitationsModId).next_link/5 examines the links on the current page (of type PageType and of URL PageURL) to determine the next page to visit, returning its type (i.e., NextPageType) and URL (i.e., NextPageURL). The choice of page is constrained by the list of project names in Projects, obtained earlier from contains/2.
The definition of next_link/5 is as follows:
next_link(PageType,PageURL,Projects,NextPageType,NextPageURL) :-
precedes(PageType,NextPageType),
m_id(PageURL)#>link(Label,NextPageURL),
useful_link(Projects,NextPageType,Label,NextPageURL).One technique used in useful_link/4 is to analyse the link's label, which is a string, to see if the page it leads to is of type NextPageType. This is achieved by matching the words in the label string against particular cue words. For some page types, the cue words are stored in cue_word/2 facts. For instance, the word ``Research'' is a cue word for pages of type research:
cue_word("Research",research).
For other page types, the cue words may not be stored in facts. For example, the project names are used as cue words to judge links to project pages. Other heuristics useful for constraining search are described in [19].
extract_modURL/2 uses similar techniques to useful_link/4 to find the database module URL on the researcher's page.
This example illustrates how the techniques of knowledge representation and automated Web search can be used to implement complex processing of queries on lightweight deductive databases. Logic programming rules are used to represent a concept hierarchy, and to specify search behaviour over Web pages. The former maps a section name to its component project names, while the latter handles changes to the contents of the Web pages.
The concept hierarchy has the drawback that it needs to be updated if a research section, group, or project, is added or removed. However, this can be done automatically, i.e. by parsing the information on the research page into logic programming facts. In fact, a script has been written which parses the page containing information on sections, groups, and projects at the University of Melbourne into logic programming facts.
The facts and rules of the previous subsections reside in a separate module at the Web site. This module is loaded first, and other pages and database modules are loaded during query evaluation.
Dobson et al [10, 11] utilise additional HTML tags to embed relational databases (called lightweight databases) in Web pages. Essentially, an entity-relationship diagram is mapped onto the hypertext structure of the Web. Relationships between entities on different pages are specified by hypertext links, with attributes defining the relationships. Lightweight databases have been used to generate HTML documents, for indexing, and for databases spreading over several servers.
Our work is motivated by their use of relational databases. However, we employ deductive databases to provide more powerful modelling capabilities. We can also specify module composition in logic programming rules.
Sandewall [23] proposes the World-Wide Data Base, where a database consists of downloadable short text files, each file containing an object description. An object consists of properties, represented in a specialised language, and can reference other database files (i.e., objects), or HTML pages. Other object-oriented concepts, such as message-passing, are not employed. The main application discussed is HTML page generation, where objects store resources for the generation of pages. In particular, values of properties may be scripts (in LISP) that specify how to generate HTML expressions.
Our databases are deductive, whereas theirs are object-based. However, their objects can be expressed in our language. Also, they do not provide a uniform query language for their objects database, while we use logic programming for that purpose.
Their use of one file per object may incur heavy network transmission costs. In our approach, modules can contain multiple relations.
Our approach to implementing lightweight deductive databases uses Prolog with LogicWeb extensions. However, existing deductive database systems [22, 15] differ from Prolog systems in several ways, including:
Another common restriction is that all terms in the program are variables or constants. This ensures that logical entailment is decidable. A logic programming language with this restriction is Datalog [22].
A major difference between our lightweight deductive databases and existing deductive database systems is that our databases are not updateable. If updates were possible, transaction processing, and concurrency control would also have to be available. We have not yet considered updates because the main focus of this work is structuring information on the Web.
The Information Manifold [18, 17] is a system for building a knowledge base representing the user's interests. This uses a combination of Horn rules and the CLASSIC knowledge representation language to describe information sources, and taxonomy relationships among them. The knowledge base is also used to process the results of searches submitted to multiple Web index servers.
Our framework supports knowledge-based query processing. Users can build their own knowledge base and query processing rules, perhaps on top of those provided by information servers.
Web pages have been generated from knowledge bases by using user profiles [16], and user queries [13]. We can achieve a similar functionality when the results of lightweight deductive database queries are Web documents.
Barcaroli et al [2] represents hypertext at a Web site using a knowledge base. Their system answers user queries by returning a sequence of links leading to the page containing the answer. In our approach, the information provider can provide a similar capability by mapping user queries to appropriate URLs.
These approaches typically make use of knowledge representation languages based on description logics in order to represent concept models. We restrict ourselves to logic programming since it is a versatile paradigm, used in a range of AI problems (e.g., expert systems and knowledge representation), and in deductive databases [24, 22].
Context logic, an extension of first order logic where sentences are true with respect to a given context, has been used to integrate databases [14]. Axioms are written which lift sentences from several contexts into a common one. This is similar to defining a new relation in terms of relations in other modules by using context switching, as shown in §3.1.
PiLLoW [8] is an Internet/Web programming library for logic programming systems. It contains a predicate to fetch Web pages, and page headers, which returns the information in term form. However, remote program modules are loaded by supplying the module's URL in a call to use_module/1.
In contrast, LogicWeb views both ordinary pages, and pages containing Prolog code, as program modules. This means that the text, and any Prolog code a page contains, are utilised in a uniform manner by goal evaluation. Moreover, LogicWeb has module combination operators.
In PiLLoW, modules (identified by a new MIME type) loaded into a local Prolog engine can be used to process queries posed via browser forms. The page containing the form is in a separate file from the Prolog module processing the form's queries. The LogicWeb system provides similar functionality, but without using a new MIME type. Also, it allows the form and the Prolog code to be situated in the same module.
The ECLiPSe HTTP-Client library [4] has a predicate to access Web pages, returning a page as a string. The same predicate can be used to download Prolog code, which is then compiled on the local system. LogicWeb has similar functionality, but expressed in terms of program modules which hide the underlying retrieval and compilation phases.
PiLLoW, the ECLiPSe library, and LogicWeb, augment existing logic programming systems with Web operators. LogiMOO [25] employs a substantially different method to execute remote Prolog code locally, based on MOOs (Multi User Domains - Object Oriented) using multi-threaded distributed blackboards. A client can create a local virtual blackboard, and connect it to a MOO. Then, the client can take objects from, or put objects onto, the MOO via this blackboard. This allows code to be retrieved and processed, using Prolog meta-programming capabilities. Also, JavaScript ``open URL'' commands returned to the client as answers to Prolog queries causes Web pages to be displayed.
The Web should be enhanced with richer information content, and more sophisticated processing capabilities [3]. Our lightweight deductive databases provide improved querying, automated searching, and sophisticated processing and extraction of structured information on the Web. Lightweight deductive databases can be easily combined, and extended during query processing, using well-established techniques from the areas of deductive databases and structured logic programming.
We conclude with several possible avenues for future work.
We have not dealt with integrity constraints in this paper. For example, the uniqueness property of primary keys must be maintained when databases are combined. There exists methods for combining knowledge bases with integrity constraints [1].
We have demonstrated the utility of a small set of composition operations, but it may be useful to explore other operations.
A modelling language (with constructs closely related to the application domain) could be used to describe particular kinds of knowledge. This may take the form of additional syntax, which can be translated into Prolog.
The structured information provided by lightweight deductive databases should be more readable by intelligent software agents [12], than plain HTML text. An interesting possibility is to use lightweight deductive databases to store agent functionality, which an agent could upload as it searches the Web.
Lightweight deductive databases must be manually generated at present. However, in some cases, lightweight deductive databases can be generated from text. For example, if citations are sufficiently marked-up in HTML, they can be converted into facts automatically. This idea is used in §4, to generate the logic programming representation of the research information.
Approaches to automatically generating new lightweight deductive databases from existing ones, given database schemas, should be investigated. Work on agent-based knowledge extraction (or data mining) from databases using Inductive Logic Programming [9], might be applicable.